
神经网络中的前向传播与后向传播
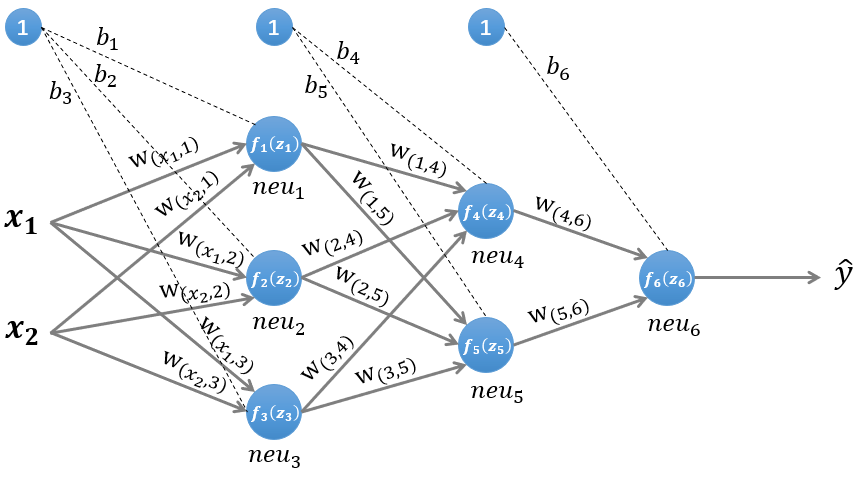
为激励函数,关于激励函数(又称激活函数)的总结
隐藏层1输入
隐藏层1输出
隐藏层2输入
隐藏层2输出
隐藏层3输入
隐藏层3输出即输出层
损失函数
即隐藏层k+1输入
隐藏层k+1输出
对损失函数进行总结https://blog.csdn.net/lien0906/article/details/78429768
计算偏导数
列向量对列向量求导参见矩阵中的求导
计算偏导数\frac {\partial L(y,\widehat y)}{\partial z^{(k)}}\
偏导数\frac {\partial L(y,\widehat y)}{\partial z^{(k)}}\ 又称误差项(error term,也称"灵敏度"),一般用 表示,用 表示第k层神经元的误差项,其值的大小代表了第k层神经元对最终总误差的影响大小
最终需要用的两个导数
后向传播参数更新
其中 是学习率
后向传播中的正则化,L1正则化,L2正则化